Mlops
[ 손쉽게 ML 라이프 사이클을 다룰 수 있는 MLOps ]
Abstract
- MLPOps 라이프 사이클 중에서도 서빙에 초점을 맞춘 부분
- 딥러닝 학습을 통해 모델이 나오더라도 여전히 서빙을 위해서는 쉽지 않음
- 딥러닝 모델 배포의 어려운 점과 모델을 배포할 때 편리하게 해주는 방법
- GPU 자원을 효율적으로 사용하지 못해 낭비하는 경우가 많은데, 모델 변경이나 AI 연구자의 노력을 최소로 하면서 자원을 효율적으로 사용하는 방법에 대해 이야기 한다.
Contents
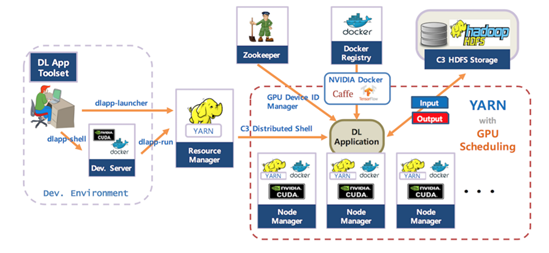
1. 딥러닝 서빙의 어려운 점
- AI 연구자와 엔지니어 영역이 다름
- 모델 개별이 되더라도 서빙을 위해 구현해야 하는 기술 스택을 공부해야 하는 어려움이 있음
- 얼마나 트래픽이 들어올지 몰라서 많은 GPU 확보하고 시작 : 자원 낭비 (GPU사용다 못함)
- 인퍼런스를 하기 위한 최소한 장비 사양을 모름
2. 모델 표준화
- AI 연구자가 만든 모델 정보를 표준화하여 엔지니어와 모델의 역할 자체를 분리함.
- AI 연구자는 모델만 전달
- 엔지니어는 모델을 받아서 서빙
- SavedModel (tensorflow에서 사용)
- ONNX (Pytorch로 사용해서 학습한 모델에서 사용 가능)
- TensorRT plan file (NVIDIA TensorRT 기술을 사용하여 GPU인퍼런스에 최적화)
- MLflow Models : 메타 데이터를 저장하기 위한 flow
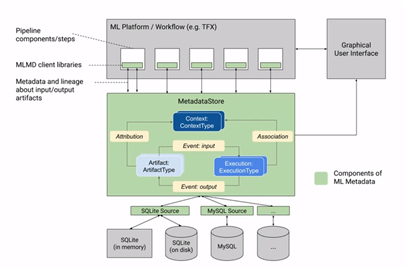
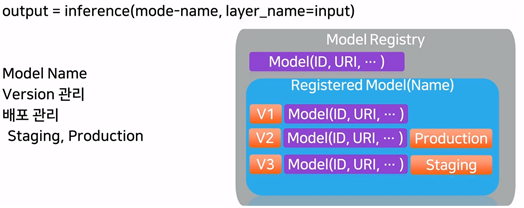
3. Model Registry
- 모델과 부가 정보를 저장하는 DB (metric, hyperparameter를 저장하는 등)
- 실제 모델 파일은 HDFS에 저장
- AI 연구자와 엔지니어를 이어주는 도구
- ML-metadata를 사용
- 서빙 서버 실행
- model-id만 가지고 inference server가 어디에서 실행되고 있는지를 찾을 수가 있음
- Load balance 조절 가능
- 에러에 대한 처리 가능
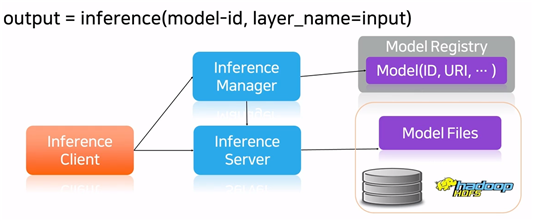
-
이후에는 버전 관리를 위해 다음과 같이 model-name을 사용한다고 함.
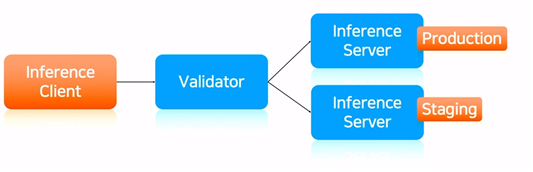
- model registry를 활용할 수 있는 방안 : model validation
- validation의 목적 : 모델을 변경했을 때, 인퍼런스 결과가 이상하게 나오는 것을 방지
- 서버에 배포하는 순간에 결과가 잘 나오는지를 확인하는 것이 중요함.
- AI 연구자나 엔지니어의 개입없이 Production, staging을 비교하기
- validation 결과를 보고 staging 상태의 모델을 production 할지를 결정하게 된다
4. 자원 최적화
- 자원낭비 이유 : 인퍼런스를 하기 위한 최소한의 장비 사양을 모름
- 트레이딩을 할 때 사용했던 사양을 그대로 인퍼런스에 사용
- 다양한 GPU 모델
- CPU에서도 테스트가 필요 : GPU에서의 사용과 차이 없는 경우
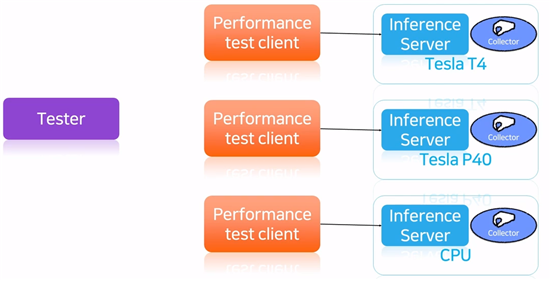
- 성능 테스트 : 인퍼런스 서버를 실행하고, 입력 하나가 있다면 이후 성능 테스트는 기계적인 과정임
- 인퍼런스 서버 실행하고,
- CPU, GPU, Memory 등 시스템 자원 모니터링
- client를 올려주면서 부하 확인
-
testor가 inference server를 실행하고, 전체 GPU에 대하여 GPU, CPU, Memory를 얼마나 사용할지를 입력으로 받아서 latency를 사용
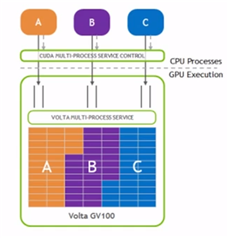
- MPS (Multi Process Service) : 한 개의 GPU를 여러 프로세스가 사용하면서 성능 저하를 최소로 해주는 기술, GPU 코어를 1/2, 1/4만 할당하는게 가능, 메모리 사용은 제한할 수가 없음.
-
성능 : GPU사용율이 낮은 작업은 성능 저하가 거의 없음.
- AutoScale : 부하에 따라서 자동으로 컨테이너를 늘리거나 줄이는 기능, 보통 CPU, MEMORY, GPU 사용율로 설정함, 잘못 설정하면 동작하지 않음 (inference server가 최대 60%까지 GPU를 사용할 수 있는데, GPU 사용율 70%일 때 늘리도록 설정하면 동작하지 않는다)
- 성능 테스트 결과가 있으니, 최대 성능의 비율로 스케일이 가능하다.