ML09. anamaly Detection, Recommender Systems
Anamaly Detection
1. density estimation
1.1 problem motivation
- anormaly는 정상적인 데이터에서 떨어진 데이터를 의미한다. 예를 들어 공장에서 품질이 떨어지는 제품을 골라낼 때 사용한다. 즉 전체 데이터셋을 주어주고, $x_test$를 대입했을 때 anoramly값인지를 판단한다.
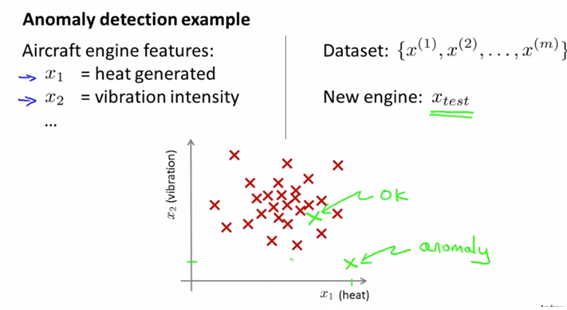
- 즉 fraud detection과 같은데서도 많이 사용되며 데이터로부터 모델 p(x)를 만들고 새로운 값이 들어왔을 때 p(x)< e인지를 검사한다.
- 혹은 Manufaturing, Monitering computers in a data center과 같은 경우에도 많이 사용한다.
1.2. Algorithm
- 기존의 anormaly를 나타내지 않을 것 같은 좋은 data로 모델을 만들고 anormaly를 잘 나타낼 것 같은 feature을 골라 p(x)를 계산하는 과정을 거친다.
- feature은 각각 정규분포를 따른다는 가정하에 pdf를 계산하여 p값을 구한다.

2. Building an anomaly detection system
2.1. developing and evaluating an anomaly detection system
-
given data중 flawed가 확실한 데이터, good example data는 training set으로 non-anmalous을 사용하고, CV, test set으로 반반씩 분할하여 사용한다.

-
위의 test split에서 볼 수 있듯이 data는 매우 skew된 형태를 취한다. : 따라서 단순히 정확도가 아니라 precision, recall, f1-score로 평가한다.

-
또한 thershold $\epsilon$을 계산하기 위해 f1-score을 최대화하는 parameter값을 구할 수 있다.
2.2 anomaly detection vs Supervised Learning
- 결국 y값이 있는 데이터라면 왜 supervised learning을 사용하지 않을까?
- anmaly detection-> skewed data의 경우에 주로 사용한다. 또한 anomaly가 굉장히 다양할 수 있기 때문에 특정한 형태로 구분짓는 알고리즘을 특별히 만들기 힘들기 떄문에 사용하지 않는다.
- ex)fraud detection, manufacturing, monitoring machines in a data center..
- supervised learning -> balanced data의 경우에 주로 사용한다(positive, negative값이 모두 large일 때 사용한다. ) 또한 이 경우는 하나의 feature에 대한 결과에 대해, 미래의 비슷한 feature이 있다면 비슷한 결과를 낼 것을 가정하고 본다.
- ex) SPAM filtering에서는 다양한 타입의 positive example이 있어도 우리가 충분한 양의 positive example이 있기 때문에 커버 가능하고 supervised learning을 사용한다.
- ex) wheather prediction, cancer classification

##23. choosing what features to use
- anormaly detection 모델을 사용하는데 필요한 feature을 selection하는 방법에 대해 설명한다.
- non gaussian feature -> transformation이 필요(로그변환 후 replot하여 확인한다)
- 혹은 다른 방법으로는 log($x_2$+c), sqrt($x_3$)등이 있다.
- p값이 noraml인 경우와 anomalouos의 경우 모두 높게 된다면 문제가 된다.
-
이런 경우엔 새로운 feature x2를 도입하여 anormaly값을 구하면 된다.
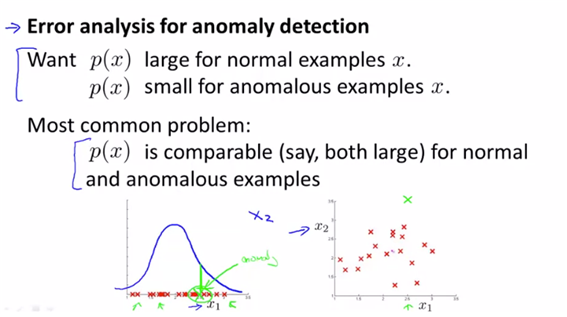
- and choose features that might take on unusually large or small values in the event of an anomaly
- ex) 데이터센터 예제로는 CPU load, network traffic이 있다. 네트워크 트래픽이 낮은데 CPU load가 높다면 확실이 anomaly이기 때문이다.
recommendation system building
3. Predicting Movie Ratings
3.1 problem formulation
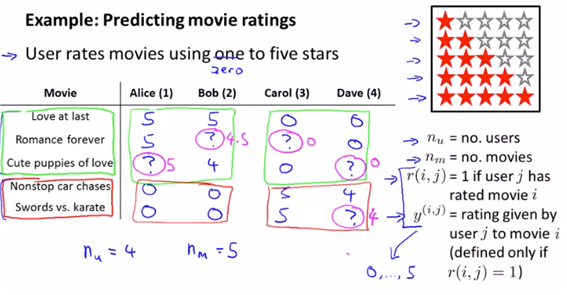
ex)기존의 성향을 바탕으로 아직 보지 않은 영화의 평점을 예측하게 하는 형태의 알고리즘이다.
- 추천 시스템의 유형
- 콘텐츠 기반의 필터링 : 사용자가 특정한 아이템을 선호하는 경우 그 아이템과 비 슷한 콘텐츠를 추천하는 방식
- 협업 필터링 : 사용자가 평가한 다른 아이템을 기반으로 사용자가 평가하지 않은 아이템을 추천-비교 대상이 다른 고객
-(최근접 이웃 협업 필터링- 사용자기반:당신과 비슷한 고객도 선택, 아 이템기반: 이 아이템을 구매한 고객이 이것도 선택, 잡재요인 협업 필터링-사용자-아 이템 매트릭스 속의 잠재요인의 선택)
4.2. Content based recommentations
- 위의 예제에 더하여, 각 영화의 장르별 feature인 x1, x2를 추가했다.(콘텐츠 기반 : 사용자가 특정 아이템을 선호하면, 비슷한 것을 추천)
-
각 영화자체의 feature에 대한 벡터를 x로 두고, 사용자의 각 영화에 대한 평점을 $\theta$라고 둔다. 그렇다면 theta.T*x값이 영화 평점에 대한 예측일 것이다.
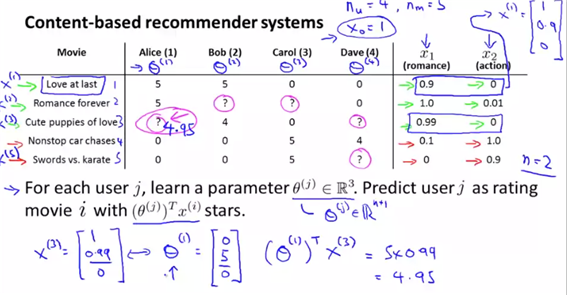
-
위의 경우는 j번째 유저로부터 theta값을 얻어 feature x를 곱합으로써 linear regression문제로 변경했다. (여기서의 theta는 rating을 의미하는 것이 아니다. -> paramter theta)
- 그렇다면 theta를 훈련하는 방법은? linear regression과 비슷하게 cost값을 최소로하는 값을 선택하게 한다. (optimization objective)
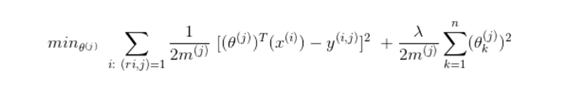
- 하지만 대부분의 경우에는 content의 feature을 제공해주지 않는다. 따라서 다음에는 content를 기반으로 하지 않는 추천 시스템을 소개한다.
4. Collaborative Filtering(협업필터링)
4.1. Collaborative filtering idea introduction
- values of feature을 모르는 dataset을 가진다. (사실상 content-based recommendation형태의 feature을 구하긴 어렵다)
- 반면에 user로부터 theta값을 얻어낼 수 있다면 이를 바탕으로 feature x를 알 수 있다.
-
$x_i$값을 얻기 위해서는 마찬가지로 cost값을 최소로 하는 I,r값을 가져야 한다.
- 즉 theta가 주어지면 x를 훈련할 수 있고 x가 주어지면 theta를 훈련할 수 있다.

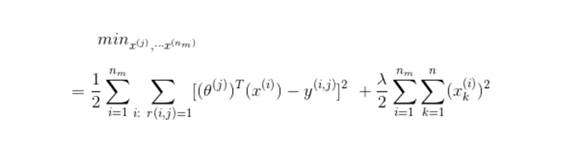
- 따라서 랜덤으로 작게 설정된 theta에 대해 theta와 x를 번갈아가면서 학습시키는 방법을 통해 학습을 진행한다.
- 즉 정리를 하자면 다음과 같다.
-
- x, theta값을 작은값으로 초기화 한다. 이는 symmetry breaking을 하기 위함이다. 작은 랜덤값들로 초기화하여 x(i)가 서로 다른 값들을 가지도록 도와준다.
-
- cost function J를 gradient descent를 이용하여 J를 최소화하는 theta와 x값을 가진다.
-
- 유저의 parameter theta와 영화의 feature인 x에 대해 theta.T*x를 이용하여 rating을 예측한다.
4.2. collabortive filtering algorithm
- 앞에서 배웠듯이 optimized objective인 theta와 x를 구하기 위해서는 J function을 고려해야 한다. 이에 대해
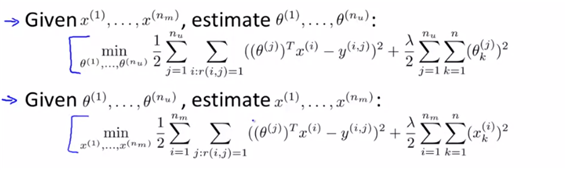
- 위의 두가지를 한번에 계산하는 형태가 효율적이므로 두 파라미터를 한번에 놓고 계산하도록 한다. (한번에 식을 계산할 수 있도록 cost를 변형)
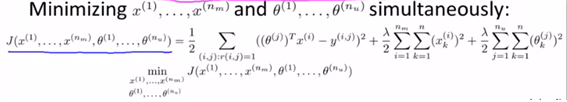
5. Low Rank Matri Factorization
5.1. vectorization : low rank matrix factorization
-
collaborative filtering을 theta와 x의 값으로 각각분해해 보면 아래와 같이 생각할 수가 있다. (결국 협업필터링을 다른말로 low rank matrix factorization이라고도 한다)

- finding relative movies(유사도 측정도 가능하다)
- 위와 같은 low rank matrix factorization을 이용하여 feature을 찾으면 두 영화의 유사도를 x_i와 x_j사이의 거리를 사용하여 판단할 수 있다. (데이터 상의 거리)

## 5.2. implementational detail : mean normalization
- 만약 user가 영화에 대한 평가를 하지 않을 상황이면 theta값이 0이 되므로 min J값을 적용하기에 좋은 상황은 아니다.
- theta.T*x=0이 되기 떄문이다.
- mean normalization은 이런 문제점을 해결한다. mean normalized데이터를 사용하면 추천 안한 사람이 theta=0을 가지더라도 남들이 추천한 선호도 u에 따라서 영화를 추천받을 수 있다.
-
mean normalization은 각 movie에 대한 average를 계산한다. 그리고 이 평균값과 각 value와의 차잇값을 새로운 행렬로 작성한다. 그리고 그 행렬을 협업필터팅의 데이터로 사용한다.

- 위에서 보는 것과 같이, predict할 때는 normalize한 값을 다시 원래의 값으로 돌려줘야 하기 때문에 mean값을 돌려줘야 한다.
딥러닝으로 구현한 추천 시스템
- youtube의 알고리즘이 대표적으로 뉴럴 네트워크로 구성한 추천 시스템
- 첫 번째는 후보를 생성하는 것이고 그다음은 그것을 순위화 하여 추천하는 방식이다
- 위의 과정을 좀더 설명하자면, 우선 사용자에게 추천할 후보군을 수백개 뽑는 1단계 후보 모델, 그리고 그 수백개의 후보들이 사용자가 얼마나 관심있을지에 대한 점수를 계산하는 2단계 랭킹 모델이 있다. (후보군을 줄인다음 랭킹을 계산하여 성능을 높인다)
1. 후보모델 선정
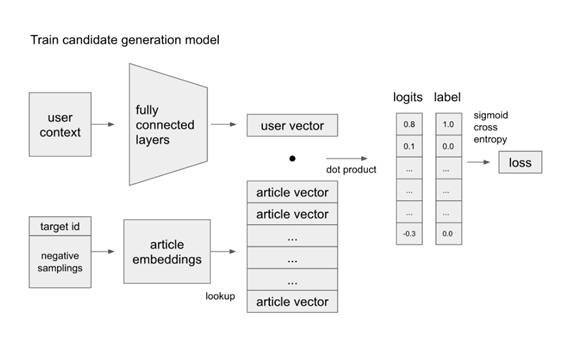
- user의 상황을 바탕으로 layer을 만들어 user vector을 만든다. target id와 sampling을 통해 워드 임배팅을 시행하여 article vector을 만든다. 두 벡터값을 내적하여 각 user의 context별 관심있는 article을 내적하여 logit함수를 적용한다음 labeling을 하여 softmax출력값을 가진다. 각 매개변수에 대해서는 loss optimizer object를 사용하여 계산한다
- 즉 input(현재 시청)에 대한 target(다음시청)의 확률을 높이는 방식을 목적으로 한다.
- (원리는 matrix Fatorization과 비슷하다. “사용자 * 아이템”의 행렬이 있을 때 사용자 벡터와 아이템 벡터로 분해하고 다시 사용자 벡터와 아이템 벡터를 dor product연산을 하여 나온 값으로 점수를 예측하는 방법이 MF이고, 결국 다양한 사용자 정보를 뉴럴 네트워크로 학습하고 사용자 벡털르 생성하는 부분만 다르고 사용자 벡터와 컨텐츠 벡터를 dot porudct로 연산되는 원리는 비슷하다)
- 또한 모델을 구성할 때 빠른 실서비스에 고려된 중요한 부분은 유사 벡터 검색을 예측할 때 사용하는 부분으로, 유사 벡터 검색로 dot product을 대체할 수 있다.
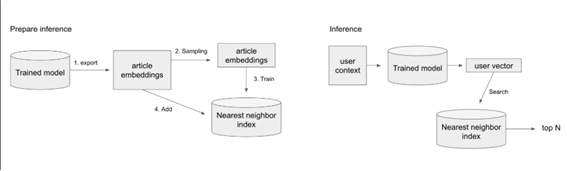
- 마지막으로 성능을 추천하기 위해 (target글을 예측한 순위가 얼마나 높은지를) MAP(=mean average precistion)을 사용한다.
2. 랭킹모델
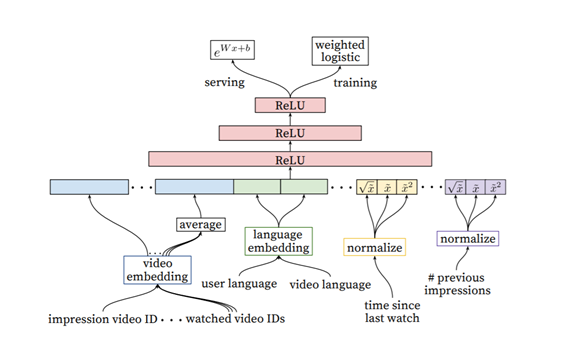
- 후보모델과는 다르게 사용자의 글과 정보를 모두 concat하여 수집한 데이터를 가지고 최종결과는 dot product가 아닌 nueral network layer에서 나와 더 정확하게 선호도를 예측하는 정도를 나타내는 regression으로 출력한다.
- 실제 구현 blog : https://medium.com/daangn/%EB%94%A5%EB%9F%AC%EB%8B%9D-%EC%B6%94%EC%B2%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C-in-production-fa623877e56a
- 참고논문 : https://static.googleusercontent.com/media/research.google.com/ru//pubs/archive/45530.pdf
- 참고 blog: https://yarmini.com/2019/01/17/%EC%B6%94%EC%B2%9C-%EC%8B%9C%EC%8A%A4%ED%85%9C-%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98-%EA%B8%B0%EC%A1%B4-%EC%A3%BC%EC%9A%94-%EC%B6%94%EC%B2%9C-%EC%97%94%EC%A7%84%EA%B3%BC-%EC%9E%91%EB%8F%99-%EB%B0%A9%EB%B2%95/
Reference
- https://1ambda.github.io/data-analysis/machine-learning-week-9/
- coursera Andrew Ng, machine learning