Kaggle Project
하계인턴 개인 project
- 7개의 kaggle project를 진행함
- 총 성적은 아래와 같다.

- kaggle project를 진행하면서 여러가지 dataset에 대한 insight를 얻을 수 있었고, 모델의 custom 방법과 automl을 직접 사용해 볼 수 있었던 경험이었음.
1. 진동데이터 활용 충돌체 감지
-
51위 (about 8.1%)
- 원자력발전소 냉각재계통 내부에서 충돌체가 충돌했을 때의 충격파를 감지하여 충돌했을 때의 위치, 질량, 속도를 예측
- 원전 현장에서는 기기의 이상징후를 조기에 진단하여 사고를 방지하고자 함.
- 주파수 특성, 타임 도메인 등을 활용하여 정확히 예측해보고자 한다.
-
즉 시간/가속도 데이터를 바탕으로 역으로 충돌물의 위치를 파악하고자 하는 것이 목표.
- 시간차이(가속도)를 추정하여 해결한다.
- 4개의 가속도 센서의 축에 따른 가속도 속도의 변화를 감지하여 2800개의 경우에 대하여 학습시킴
- 평가기준 : E1 -> 거리오차, E2-> 질량과 속도의 상대오차
- 이슈1 : 단일모델 사용 vs 다중모델 사용
- 이슈2 : 시계열 데이터를 그대로 볼 수도 있지만, 주파수 도메인 변경 혹은 data augumentation을 사용해 볼 수도 있겠다는 점.
source code
(1) 시도1.ipynb
- data를 확인해본 결과, id(충돌체별 고윳값)별로 묶어 특성을 구분할 필요가 있어, time(관측시간)과 각 센서별 가중치를 합하여 column으로 지정함
- randomforest 앙상블 모델을 사용하고 각각을 randomsearch를 사용하여 하이퍼파라미터 튜닝완료
(2) 시도2.ipynb
- 이번엔 cnn모델에 적용해보고자 함. (시도3에서는 resnet이나 vggnet을 사용해 보고자 했다)
- 먼저 데이터를 .reshape((2800, 375, 5, 1))의 형태로 변형함.
- 각 id별로 375개의 데이터가 2800개 있는 형태이므로 위와 같이 변형함.
- 노드수를 16부터 시작하여 2배씩 늘려가며 적용하고, 마지막엔 완전 연결층으로 연결
- Adam optimizer을 사용하고 batchsize는 256으로 지정함,
- 위치(x,y좌표), 질량(m), v(속도)를 따로 학습시켜 예측하는 방법을 사용함.
notation for project
- 모델을 적용하기전, 데이터를 살펴보지 않아, id를 왜 변경해줘야 하는지 이해하지 못함.
- 분석전에 데이터파일 먼저 열어서 어떻게 전처리해야 모델에 적용할 수 있는지를 반드시 생각해봐야 한다.
- ( feature의 의미 뿐만 아니라 데이터 자체가 어떻게 구성되어 있는지를 봐야 한다. )
- cnn 모델에 대한 이해가 필요했음. 이 문제에서는 multi regression을 사용하는 것보다
- cnn을 사용하는 것이 더 좋은 결과를 얻을 수 있었음. 따라서 resnet이나 vggnet 모델을 생각해봄.
- **근데 여기서 왜 cnn을 사용해야 하는지 궁금함.(결정하는 이유나 방법에 대해) **
- cnn은 이미지 데이터에서만 쓰는 방법은 아님. 2016-2017 연구에서 가장 예측력이 좋은 모델이었음
- 즉 이미지 데이터라는 것은 결국 2차원 이상의 matrix를 의미한다.
- 데이터를 2차원 이상의 매트릭스로 정리하는 것은 생각보다 간단함
- 따라서 이미지 데이터가 아닌 데이터를 어떻게든 2차원 매트릭스로 변환하여 cnn을 적용해보고자 하는 연구가 있었다.
- 자연어 인식에서 다루기도 하는 방법이다.
- rnn이나 cnn은 등장 순서가 중요한 sequential data를 처리하는데 강점을 가진다.
- cnn은 필터가 움직이면서 지역적인 정보를 추출, 보존하는 형태로 학습이 이뤄진다. 요컨데 RNN은 단어 입력값을 순서대로 처리함으로써, CNN은 문장의 지역정보를 보존함으로써 단어/표현의 등장순서를 학습에 반영하는 아키텍쳐 이다. cnn에서는 필터를 지정하고 필터 개수만큼의 feature map을 만들고 max-pooling의 과정을 거쳐 스코어를 출력하는 네트워크 구조이다. 자연어처리에서는 단어벡터를 랜덤하게 초기화한 후 학습과정에서 이를 업데이트하면서 쓰는 방법을 채택한다. 이런 방식을 사용하기 위해서는 텍스트 문장을 나열로 변환해야 한다 (참고 블로그 ㅣ https://ratsgo.github.io/natural%20language%20processing/2017/03/19/CNN/)
- 데이터 전처리 방법
- 신호데이터와 같은 경우는 푸리에를 적용하여 전처리도 가능했다는 점.
- 이슈1에 대한 해결
- 신호 데이터의 경우, 모든 신호의 class를 하나의 pooled model에 학습시킬 수도 있고, 혹은 각각의 신호에 대해 classifier를 만들고 하나의 model을 만들어 학습시킬 수도 있다.
- X,Y,M,V를 다같이 하나의 모델로 학습시키는 것보다 각각 따로 학습시키는 것이 더 좋은 결과를 얻을 수가 있었다.
- ( 더 정확히 말하면 위치 target과 질량 target, 속도 target으로 나누어 학습시킴 )
- data agumentation (데이터 증식)할 수 있는 방법?(이슈2를 사용할 수 있는 방법)
- 혹은 시계열 데이터 그대로 사용할 수도 있지만 주파수 domain을 변형하여 사용할 수 있는 방법?
(1) use pooled design or ensemble model
(2) new method for signal data
- 1) signal segmentation and recombination in the time domain.
- 동일한 class에서 데이터를 segmentation하고 random하게 선택하여 concat함으로서 artifitial한 새로운 데이터를 생성한다
- 동일 class내에서 하는 작업이므로 feature를 해치치 않는 관점에서 유용한 방법이다.
- 실제로 covariance matrix를 통해 LDA classifier를 사용한 것과 다를 바 없음을 보일 수 있다. - 2) signal segmentation and recombination in the time frequency design
- 앞의 방법대로 한다면 단순히 segment값을 concat하는 방식이므로 원치 않는 noise가 발생하게 된다.
- 이를 해결하기 위해 “time frequency domain”을 사용한다.
- transform each bond-passed filtered training trial Ti in a time-frequenct representation TFi using STFT.
- TFI_k는 결국 kth time window를 의미한다.
- 즉 concatenating together using STFT windows를 하면서 새로운 artifitial data를 생성한다. - 3) aritifitual trial genertion based on analogy.
- “computing transformation to make trial a similar to trial B and then applying this transformation to trial C and create artifitial trial D”
- 먼저 각 class 의 available data에 대하여 covariance matrix C를 구한다.
- 이를 바탕으로 고유벡터 V를 구한다 (Princopal Component in data)
- and randomly select 3 distinct trials Xa, Xb, Xc
- project first two of them to the PC of data and compute signal power pa_i and pb_i.
- make Xd using Xc (참고 논문 | Signal processing approaches to minimize or suppress calibration time in oscillatory activity-based Brain-Computer Interfaces )
- 혹은 시계열 데이터 그대로 사용할 수도 있지만 주파수 domain을 변형하여 사용할 수 있는 방법?
(1) use pooled design or ensemble model
(2) new method for signal data
resnet, vggnet architecture
- residual net : using shortcut and skip connection allows the gradient be directly backpropagated to earlier layers.
- the identitiy block is the standard block used in ResNets, and corresponds to the case where the input activation has the same dimention as the output activation
- the convolutional block is the other type of block. I can use this type when the input and output dimentions don’t match up.
- why do skip connections work? 1) they mitigate the problem of vanishing gradient by allowing this alternate shortcut path for gradient to flow throught 2) they allow the model to learn an identity function which ensures that the higher layer will perform at least as good as the lower layer, and not worse.
- cnn은 학습완료함. resnet은 안되는 이유?
- resnet에서 weight와 train_target이 꼬여 있어서 문제 발생
- 원래 keras.application,resNet50을 사용하면 각각 학습이 불가능하다.
- 따라서 resNet50 library를 뜯어서 각각 학습이 가능하도록 만들었음.
- 바꾼 부분은 해당하는 weight의 경우, loss를 위치 / 질량과 속도에 따라 다르게 구하므로 이를 각각 weight를 지정하면서 지정해 주었다.
- 또한 ensemble design로 만든 형태이므로, 각 weight를 원래 라이브러리에서 지정하는 형태가 아닌 다른 형태로 가져와 지정해 줬다.
2. Real or Not? NLP with Disaster Tweets(NLP)
- predict which tweets are about real disasters and which ones are not.
- 트위터는 긴급상황에서 중요한 커뮤니케이션 채널이다.
- 스마트폰의 편재성 덕분에 사람들은 실시간으로 관찰중인 비상상황을 발표할 수가 있다. 이로 인해 많은 대행사가 프로그래밍 방식으로 Twitter를 모니터링하는데 관심이 많다.
- 그러나 사람의 말이 실제로 재난을 알리는지 여부가 항상 명확한 것은 아니다
- 실제 재난에 대한 트웻과 그렇지 않은 트윗을 예측하는 기계 학슴 모델을 구축하고자 한다.
source code
(1) tweeter_disaster_baseline.ipynb
- txt 데이터를 counter vectorize화 하여 분석하고자함
- Ridge Classifier, xgboost + tuning classify
(2) tweeter_disaster_2.ipynb
- BERT ( https://arxiv.org/abs/1810.04805) 논문 읽고 구현
- BERT 적용해봄
model notation for project
NLP model
1. RNN, LSTM
- 결국 LSTM은 RNN에 cell state를 추가한 형태이다.
2. seq2seq2
- 입력값을 받아 벡터 c^2로 변환해주는 encoder와 encoder에서 출력된 값을 입력으로 받아 conditional probability를 고려하는 decoder로 이루어 진다.
- 하지만 입력 시퀀스가 매우 길 경우에는 long time dependencies 문제가 일어난다. 일반적으로는 LSTM이 이를 해결하나, 아직 문제가 존재한다.
- 이 때문에 입력 시퀀스를 뒤집어 디코더에서 인코더의 부분까지를 단축하여, 보다 좋은 성능을 보이기도 한다. (왜 뒤집으면 경로가 단축되지? : 전체 평균거리는 유사하나, 1대1로 매핑되었을 때의 거리가 가까워진다, 처음 값을 제외한 나머지 출력층의 추측의 경우는 seq특성상 앞쪽 5가 추측이 되면 short term dependancy를 이용하여 추측이 쉬워진다. 따라서 속도나 정확도가 올라간다. ) (이렇게 되면 문맥적인 학습이 잘못되지 않는지? : google 신경망 번역기에서는 인코더 레이어중에 섞여있음. 섞어 쓰면서 long term dependancy를 줄이는 방식으로 앙상블로 쓰인다. )
- 혹은 입력 시퀀스를 두번 반복하여 네트워크가 더 잘 기억하도록 도움을 주기도 한다.
3. attention
- 논문 : https://arxiv.org/pdf/1409.0473.pdf
- 참고 : http://docs.likejazz.com/attention/
- attention은 모델로 하여금 “중요한 부분만 집중”하도록 만드는 것이 핵심이다.
- 디코더가 출력을 생성할 때 각 단계별로 입력 시퀀스의 각기 다른 부분에 집중할 수 있도록 만든다.
- 즉 encoder에서 벡터로 변환할 때 정보 소실이 일어날 수 있는 부분을 조정하는 형태이다.
- 즉 하나의 고정된 컨텍스트 벡터로 인코딩 하는 대신에 출력의 각 단계별 컨텍스트 벡터를 생성하는 방법을 학습니다.
- 이는 모델이 입력 시퀀스와 지금까지 생성한 겨로가를 통해 무엇에 집중할지를 학습하는 방식이다.
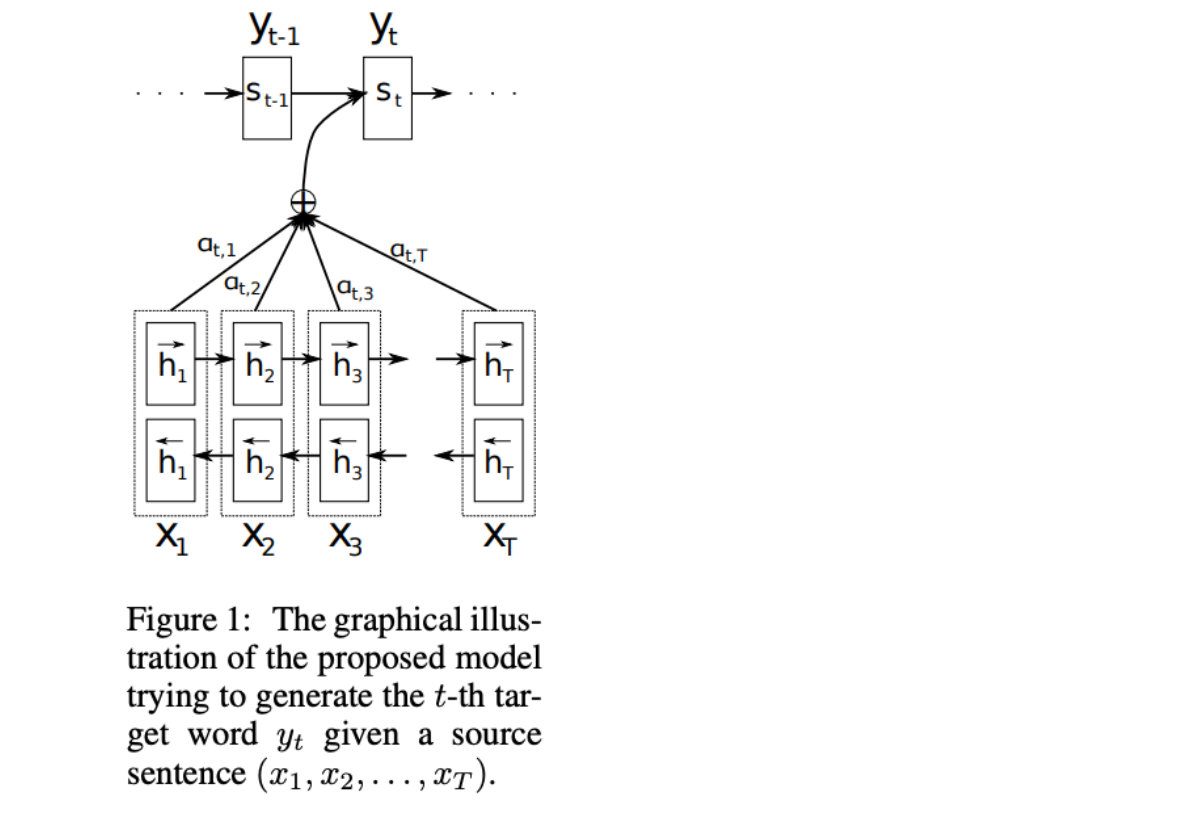
- 위 그림에서 중요한 점은 출력단어 y_t가 마지막 상태 뿐 아니라 입력 상태의 모든 조합을 참고하고 있다는 점이고 여기서 a는 각 출력이 어떤 입력을 더 많이 참고하는지에 대한 가중치를 의미한다.
- 즉 encoder seqeunce에서 contexts로 넘겨줄 때 which encoded charaters to weght high를 보고자 하는 형태이다.
4. transformer
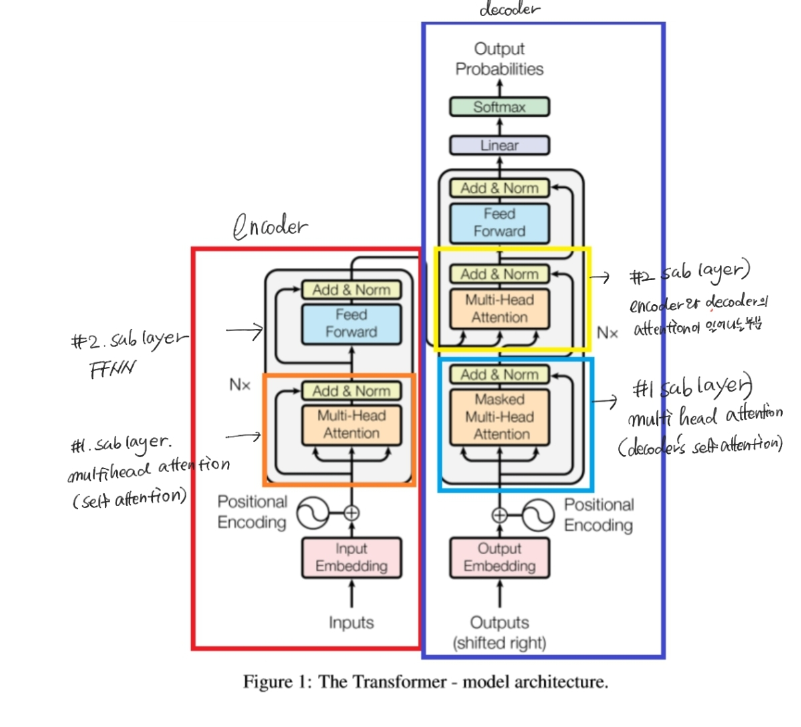
- seq2seq의 구조인 encoder, decoder을 따르면서도, attention만으로 구현한 모델이다.
- 이 모델은 RNN을 사용하지 않고 어텐션만을 사용하여 인코더-디코더 구조를 만들어 학습 속도가 매우 빠르다는 장점이 있다.
- 앞에선 어텐션을 단순히 RNN을 보정하는 용도로 사용했으나, 보정을 위한 용도가 아닌, 아예 어텐션으로 인코더와 디코더를 만들어보고자함.
- transformer는 RNN을 사용하진 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지하고 있습니다. 다만 다른점은 인코더와 디코더의 단위가 N개가 존재한다는 점입니다.
- RNN이 자연어처리에서 유용했던 점은 단어의 위치에 따라 단어를 순차적으로 입력받아 처리하는 RNN의 특성에 의해 단어의 위치정보를 가질 수 있었다는 점에 있었습니다. 하지만 transformer는 입력을 순차적으로 받는 형식이 아니므로, 단어의 위치 정보를 다른 방식으로 알려줄 필요가 있다.
- 이렇게 단어의 위치 정보를 알려주기 위해 embedding vector에 위치 정보들을 더하여 입력으로 사용하는 방식을
positional encoding이라고 한다. - 어텐션의 종류는 (1) encoder self-attention (2) masked decoder self-attention (3) encoder-decoder attention이 있다.
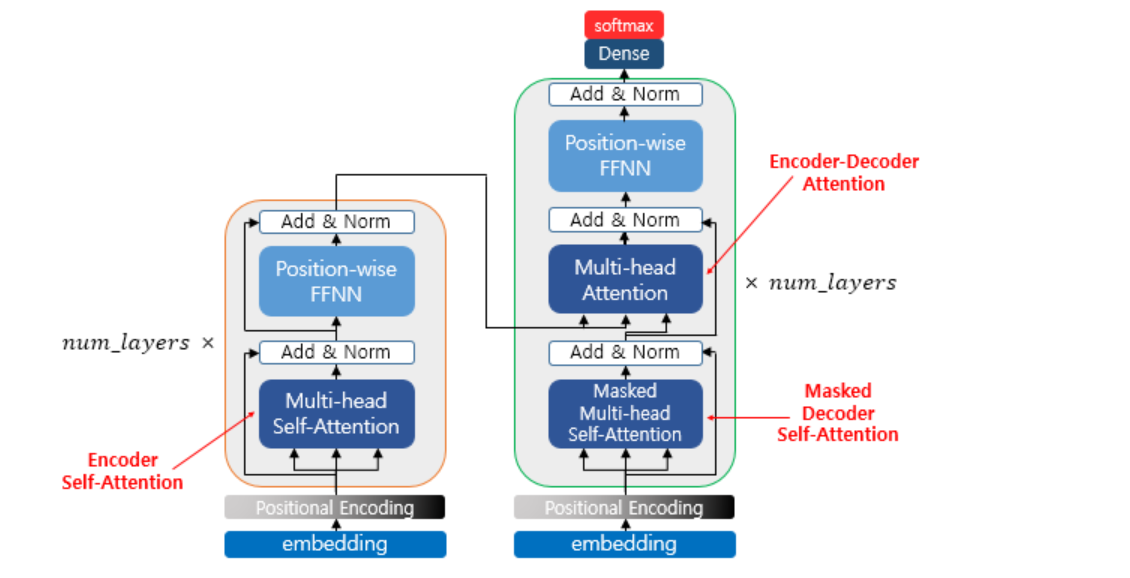
(1) 인코더
- 해당논문에서는 총 6개의 인코더 층을 사용한다.
- 인코더를 하나의 층이라는 개념으로 생각하면 하나의 인코더 층에는 2개의 서브 층이 존재한다.
- 먼저 멀티 헤드 셀프 어텐션은 어텐션을 병렬적으로 사용했다는 의미이고, FFNN은 일반적인 feedfoward의 모양이다. 1) 인코더의 멀티-헤드 어텐션
- 어텐션함수는 주어진 Query에 대해서 모든 key와의 유사도를 각각 구하여 이 유사도를 가중치로 하여 키와 매핑되어 있는 각각의 value에 반영해준다. 그리고 유사도가 반영된 값을 모두 가중합하여 리턴한다.
- 예를들어 input 값으로 <The animal didn’t cross the street because it was too tired.>에서 it이 의미하는 바를 문장 내 단어끼리의 유사도를 구함으로서 유사도 높은 단어를 골라냄으로서 알아낸다는 의미이다.
- 셀프 어텐션이 일어나는 과정은 사실 각 단어 벡터들로부터 Q벡터, K벡터, V벡터를 얻는 작업을 거쳐 이 벡터들을 초기 입력인 d_model의 차원을 가지는 단어 벡터들보다 더 작은 차원을 가지는데, 논문에서는 d_model=512차원을 가졌던 벡터들을 64의 차원을 가지는 Q, K, V벡터로 변환했다.
- 여기서 구한 벡터를 이용하여 attention score을 구하고 softmax함수를 거쳐 attention value를 얻는다.
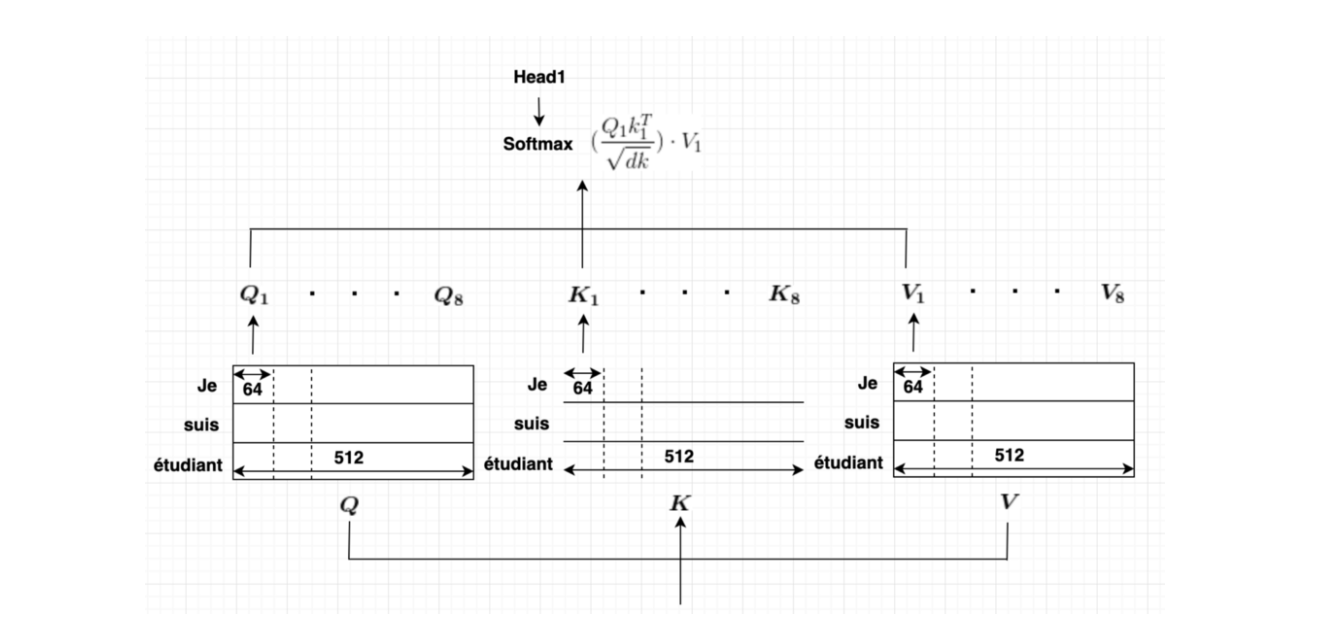
- 기본적으로 한번의 어텐션을 하는 것보다 여러번의 어텐션을 병렬로 처리하는 것이 더 효과적이므로 d_model을 num-head개로 나누어 d_model / num_heads의 차원을 가지는 Q,K,V에 대하여 num-heads개의 병렬 어텐션을 수행한다. 2) position -wise FFNN
- multi-head self attention의 결과로 나온 각 값을 FFNN을 정하여 output값을 얻는 작업을 말한다. ***3) residual connection & layer normalization
- 잔차연결 참고논문 : https://arxiv.org/pdf/1607.06450.pdf
- 층 정규화 참고논문 : https://arxiv.org/pdf/1607.06450.pdf
(2) 디코더
- 인코더와 거의 비슷하나, self-attention시 masked-multi head attention을 사용한다는 점이 다르다. -masked를 사용하는 이유는 self attention시 자신의 time step이후에 word는 가려 self-attention되는 것을 막는 역할을 한다.
- 마지막으로 encoder의 K와 V, decoder의 Q를 서로 attention시켜 위의 seq2seq모델과 종일하게 encoder과 decoder 사이의 관계를 attention시킵니다
5. BERT(이외에 Open AI, ELMo보다 좀더 발전된 형태의 모델이다)
- 논문 : https://arxiv.org/pdf/1810.04805v2.pdf
- 참고 블로그 : https://mino-park7.github.io/nlp/2018/12/12/bert-%EB%85%BC%EB%AC%B8%EC%A0%95%EB%A6%AC/?fbclid=IwAR3S-8iLWEVG6FGUVxoYdwQyA-zG0GpOUzVEsFBd0ARFg4eFXqCyGLznu7w
- 대용량의 unlabled로 모델을 미리 학습시킨 후, 특정 task를 가진 labled data로 transfer learning을 하는 모델
- OpenAI GPT나 ELMo의 경우는 대용량 unlabled corpus를 통해 language model을 학습하고, 이를 토대로 뒤쪽에 특정 task를 처리하는 network를 붙이는 비슷한 방식을 사용하나, 이 방식들은 shallow bidirectional 혹은 unidirectinal하므로 부족한 부분이 있다.
- BERT의 경우는 특정 task를 처리하기 위해 새로운 network를 붙일 필요 없이 BERT모델 자체의 fine-tuning을 통해 해당 task의 state-of-the-art를 달성한다.
- feature based approach : 특정 task를 수행하는 network에 pre-trained language representation을 추가적인 feature로 제공하여 두개의 network를 붙이는 방식이다. (ELMo)
- fine-tuning approach : task-specific한 parameter을 최대한 줄이고, pre-trained된 parameter들을 downstream task학습을 통해 조금 바꿔주는 방식이다. (OpenAI GPT)
- BERT pre-training의 새로운 방법론은 아래의 2가지이다. (1) Masked Language Model(MLM) : input에 무작위하게 몇개의 token을 mask시키고 이를 transformer구조에 넣어 주변 단어의 context만을 보고 mask된 단어를 예측한다. BERT에서는 input전체와 mask된 token을 한번에 transformer encoder에 넣고 원래 token 을 예측하므로 deep bidirectional 이 구현된 형태라고 볼 수가 있다. (2) next sentence prediction : 두 문장을 pre-training시에 같이 넣어 두 문장이 이어지는 문장인지 아닌지를 맞추는 것이다.
use BERT model
- other note books use other pooling and other CLS embeddings, but I just use model as paper mentioned.
- no pooling, directly use the CLS embedding.
- no dense layer, simply add a sigmoid output directly
- fixed parameters
BERT paper specification



3. 제주 신용카드 빅데이터 분석대회
- 궁극적으로는 코로나시대에 어떻게 소비패턴이 변화했는지를 예측하여
- 소비를 예측해보고자 하는 형태이다.
issue in this project
이슈1 : 잠재요인이 무엇이 있을지에 대한 생각
- 다른 지역에서 돈을 썼을 때
- 이를 이용한 새로운 다중모델을 생성하고자 한다.
- 혹은 현재 feature들을 어떻게 다룰 것인지에 대한 생각을 해야 한다.
- model은 CNN모다 LGBM + RF를 사용한 모델의 acc가 더 높았다.
이슈2 : 안정된 모델의 사용 for private score
- 해당 score은 2020년 4월의 값을 예측하려고 하므로, 2020 3월의 값을 가져오는 경우 큰 변화가 없다. 하지만 private score을 고려하면 좀더 안정한 방법을 사용해야 한다.
- 또한 AMT에 대한 전체 plot을 그려보면 패턴이 그려진다. 이 패턴을 활용하여 acc를 높일 수 있는 방법이 있는지가 궁금하다.
EDA 및 data cleaning
- 잠재요인 생성해보고 싶음 (해보기)
- 각 feature에 대해 PCA ( 가구 생애주기 ) : CSTMR_CNT
- 어떤 가구유형의 경우 많이 쓰는지 궁금함
- 어떤 연령대에 따라 많이 쓰는지 궁금함
- 년, 월에 따른 패턴을 파악하여 나눠주는 작업이 필요한지 (어떤 변수가 작용할 수 있는지를 생각해봐야 한다. )
- 거주지역과 카드 이용지역이 다른 경우 어떤 지역인지
- 이용건수와 이용액 확인
- y값은 총 사용금액
- 날짜에 따른 사용패턴은 파악할 필요가 없음.
- 다만 지역별로 묶어서 사용패턴을 파악할 필요는 있다.
- 총 시도의수 17개만큼 존재한다.
- 기본적으로 사는 곳에서 많이 떨어질수록 많이 소비하지 않나 생각 -주거지역이 같은 경우의 수 count : x축, 총사용엑 count : y축 을 확인하여 k-means를 진행하여, 군집화 진행, 해당 시도별로 다른 가중치를 가지고 예측하도록 한다. (결국 다른 시도일 경우엔 “destination”을 기준으로 얼마를 사용할지 결정 전반적인 트렌드라고 생각 : 해당 지역에선 뭘하는지가 거의 정해져 있으므로)
modeling
- use CNN model
- CNN모델을 변형하여 어떻게 사용할 수 있을지에 대한 생각해보기 (two-stage model을 heirachical방법으로 unified의 형태로 바꿀 수도 있겠고, 새로운 개념의 pooling 층을 추가하여 성능을 향상시킬 수도 있겠다. 혹은 BtoB transfer-learning을 사용하여 좀더 성능을 높일 수도 있다.)
- LGBM model + Random Forest model을 사용한다.
4. Google AI open images competition
- object detection에 있어서 컴퓨터가 정확안 이미지 설명을 제시할 수 있도록 매우 큰 훈련 set을 제공하여 최첨단 성능을 능하가는 정교한 물체 및 관계탐지 모델에 대한 연구를 자극하기 위한 대회이다.
- google AI는 공개 이미지 데이터셋을 공개하여 open image는 현재 전례없는 규모로 PASCAL VOC, ImageNet 및 COCO의 전통을 따른다.
- open images challenges는 open image 데이터셋을 기반으로 한다.
source code
(1) faster_rcnn_inception_resnet_v2_baseline.ipynb
- tensorflow hub에서 mululer를 사용하여 모델과 image를 graph에 넣고 실행
- resnet + Faster RCNN 사용
(2) yolo v3.ipynb
(2) FPN ( feature pyramid network ) custom model
1. Dataset
- No external dataset.
- I only use FAIR’s ImageNet pretrained weights for initialization, as I have described in the Official External Data Thread.
- Class balancing.
- For each class, images are sampled so that probability to have at least one instance of the class is equal across 500 classes. For example, a model encounters very rare ‘pressure cooker’ images with probability of 1/500. For non-rare classes, the number of the images is limited.
2. Models
- The baseline model is Feature Pyramid Network with ResNeXt152 backbone.
- Modulated deformable convolution layers are introduced in the backbone network.
- The model and training pipeline are developed based on the maskrcnn-benchmark repo.
3. Training
- Single GPU training.
- The training conditions are optimized for single GPU (V100) training.
- The baseline model has been trained for 3 million iterations and cosine decay is scheduled for the last 1.2 million iterations. Batch size is 1 (!) and loss is accumulated for 4 batches.
- Parent class expansion.
- The models are trained with the ground truth boxes without parent class expansion. Parent boxes are added after inference, which achieves empirically better AP than multi-class training.
- Mini-validation.
- A subset of validation dataset consisting of 5,700 images is used. Validation is performed every 0.2 million iterations using an instance with K80 GPU.
4. Ensembling
- Ensembling eight models.
- Eight models with different image sampling seeds and different model conditions (ResNeXt 152 / 101, with and without DCN) are chosen and ensembled (after NMS). Final NMS.
- NMS is performed again on the ensembled bounding boxes class by class. IoU threshold of NMS has been chosen carefully so that the resulting AP is maximized. Scores of box pairs with higher overlap than the threshold are added together. Results.
- Model Ensembling improved private LB score from 0.56369 (single model) to 0.60231.
(4) Detectron2.ipiynb
- this model is based on detectron, mask-rcnn
Object detection
- 이미지의 classification에서 확장되어, 해당 클래스에서 어떤 위치에 어떤 물체가 있는지를 보고자 하는 것이다. (실 세계에서의 dection)
- 참고논문 : https://aaai.org/Papers/AAAI/2020GB/AAAI-ChenD.1557.pdf
- dectection을 한다고 했을 때 R-CNN, Fast R-cnn, Mask R-CNN, YOLO, YOLO v2 등이 있다.
- 최초가 된 분석 방법이 R-CNN이고, selection search를 보완한 것이 Fast-CNN 이다. 여기서 다시 보완한 모델이 Faster R-CNN이다. YOLO의 경우는 Fater R-CNN보다 속도가 빠르나 예측율이 떨어진다.
- 결국 Yolo와 Fater R-CNN은 trade off의 관계가 있다고 본다.
- CNN
- convolution layer을 통해 feature mapping이 이루어지고 pooling을 통해 고정된 벡터로 바꿔주어, FC로의 연결이 가능하게 한다.
- R-CNN
- it propose regions, classify propsed regions one at a time. output label + bounding box.
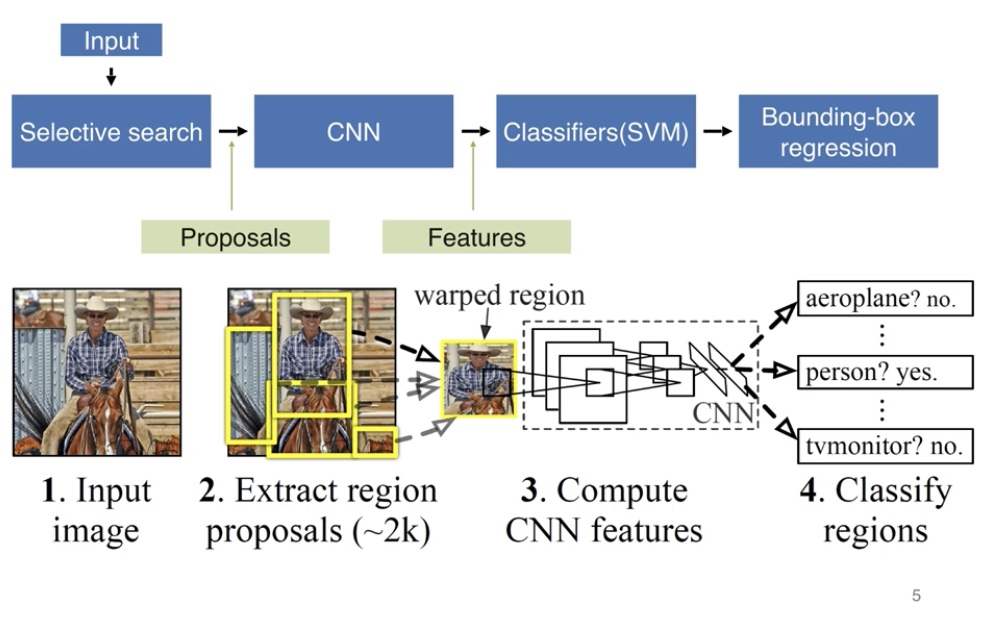
- 결국 분류기를 실행한 region을 골라내서 classifier가 일어나게 한다는 점.
- 이렇게 N=2000개를 골라내어 classifier를 실행하게되는데 이것을 이미지의 모든 곳을 찾아서 classify하는것보다 훨씬 적은 노력이 들어가는 형태이다.
- (1) input image, (2) extract region proposals using selective search(이미지 속에 class가 존재하는 예상 후보 영역을 구함)
- (3) compute CNN features(warped region으로 동일한 크기의 이미지로 변환후에 feature map을 형성), (4) classify regions(classifies like SVM)
- (5) bounding box regression (결과물이 어디에 위치해있는지까지 보정)
- selective search를 사용하여 약 2000여개의 region proposal이 이루어 진다는 점, multi stage로 세 단계의 학습이 이루어 진다는 점 (Conv fine tune(CNN의 feature mapping) -> SVM classifier -> BB regression)
- 하지만 합성곱 신경망 입력을 위한 고정된 크기를 위해 warping/crop을 사용해야 하며 그 과정에서 데이터 손실이 일어난다는 점.
- 2000개의 영역마다 CNN을 적용하기에 학습 시간이 오래걸린다는 점,.
- 학습이 여러 단계로 이루어지며 이로 인해 긴 학습 시간과 대용량 저장 공간이 요구된다는 점.
- it propose regions, classify propsed regions one at a time. output label + bounding box.
- SPPNet
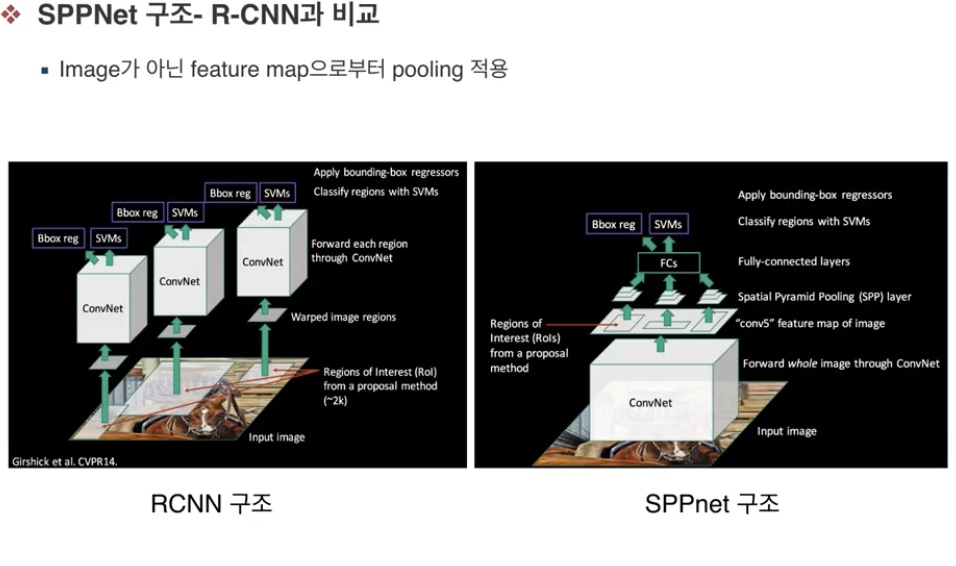
- input data를 conv layer을 통과하면서 feature map을 형성하고 이 feature map으로부터 region proposal이 이루어진다는 점. (이미지 자체를 conv network에 넣은 후에 SPP(spatial pyramid pooling) 방법을 사용하여, 고정크기 벡터로 만들어준다는점 )
- SPP를 활용하여 R-CNN의 느린 속도를 개선한다.
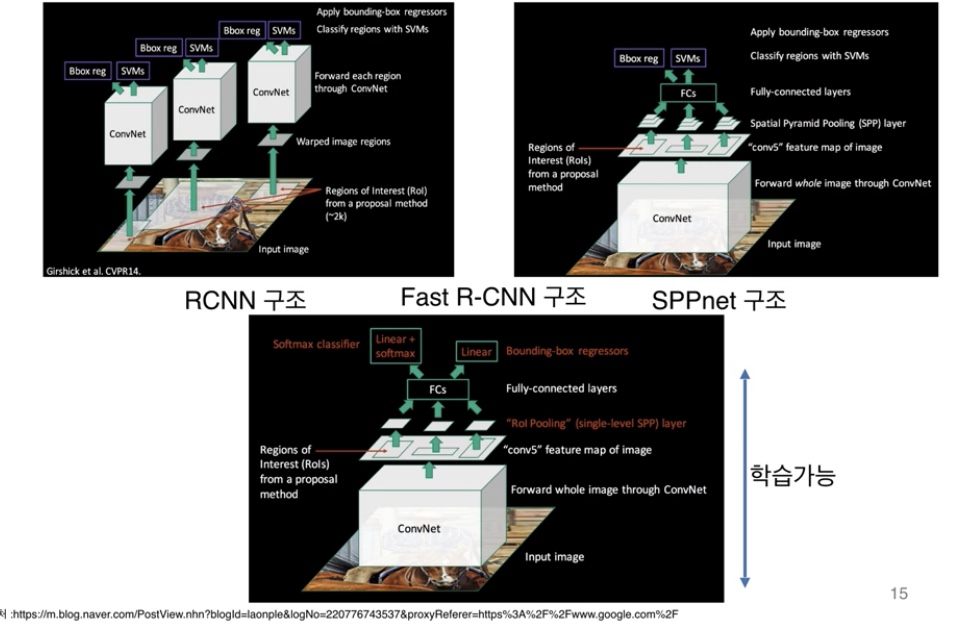
- Fast R-CNN
- propose regions. use convolution implementation of sliding windows to classify all the proposed regions.
- 원래의 구현은 한번에 하나의 지역을 분류해냈음. 여기서는 sliding window를 사용하여 여러개를 동시에 classify가 가능하다는 점.
- R-CNN&SPPnet의 한계로, 학습이 multi-stage로 진행된다는 점, 학습이 많은 시간과 저장 공간을 요구한다는 점, 실제 object detection이 느리다는 점.
- Fast R-CNN을 통해서 더 좋은 성능을 획득하며, single-stage로 학습하고, 전체 네트워크 update가 가능하게 하고, 저장 공간이 필요하지 않으며 더 빠른 시간내 학습하도록 한다.
학습과정
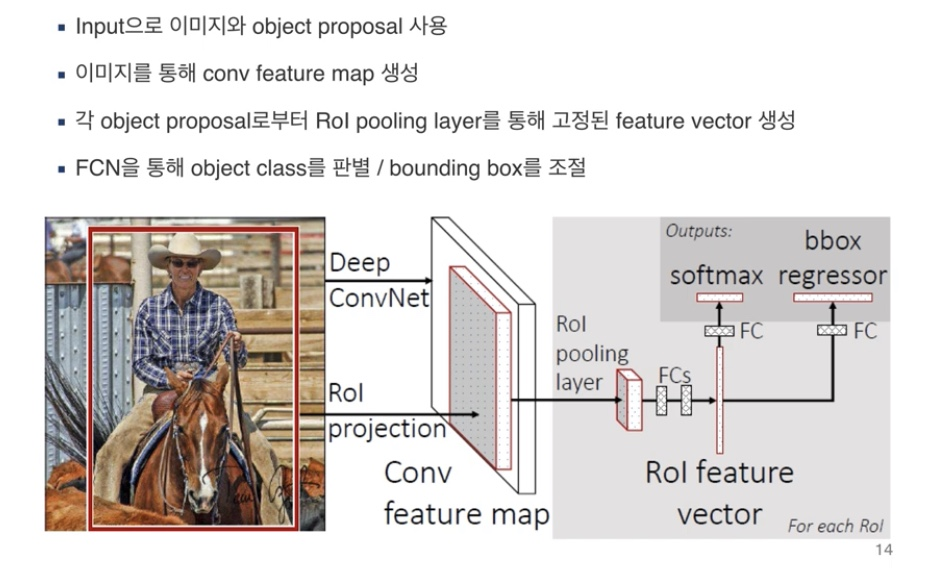
- input이미지와 object proposal 사용
- 이미지를 통해 conv feature map 생성
- 각 object proposal로부터 Rol pooling layer를 통해 고정된 feature vector 생성(FCN과의 연결을 위함)
- 결국 여기서의 ROI pooling layer는 Sppnet에서의 SPP layer와 동일하다고 생각하면 된다.
- FCN을 통해 object class 를 판별(soft max classifier과 동일) / bounding box를 조절
ROI pooling layer?
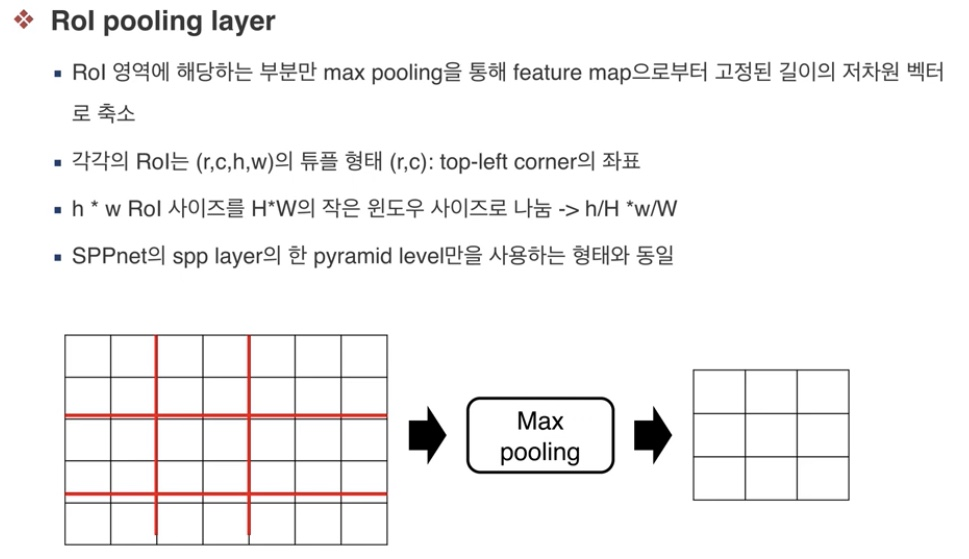
- ROI(region of interest) 영역(=알고자하는 후보 영역)에 해당하는 부분만 max pooling을 통해 feature map으로부터 고정된 길이의 저차원 벡터로 축소
- 각각의 ROI는 (r,c,h,w)의 튜플 형태로 이루어져 있다.
- 결국 h*w ROI 사이즈를 작은 윈도우 사이즈로 나눈다.
- SppNet의 spp layer의 한 pyramid level만을 사용하는 형식과 동일하다.
학습을 위한 변경점
- imagenet을 사용한 pre-trained model을 사용한다.
- 마지막의 max pooling layer가 RoI pooling layer로 대체한다
- 신경망의 마지막 fc layer와 softmax단이 두개의 output layer로 대체된다. (원래는 이미지넷 1000개 분류)
- 신경망의 입력이 이미지와 ROI를 반영할 수 있도록 반영 (이미지로부터 구한 ROI를 둘다 입력으로 사용할 수 있도록 변경을 줌)
detection을 위한 fine-tuning
- region-wise sampling -> hierarachical sampling : 원래는 N=128개의 이미지로부터 sampling을 진행했었음, 하지만 이미 지정한 N=2개에서 R=128개를 만들어 학습을 진행하여 진행속도를 향상시킨다는 점.
- single stage : 최종 classifier과 regression까지 단방향 단계로 한번에 학습이 이루어지므로 학습 과정에서 전체 network가 업데이트 가능
Fast R-CNN detection (결국 ROI를 얻어내어 그 곳에 대해서 적용한다는 점)
- 실제 환경에서 보통 2000개의 ROI, 224*224 scale과 비슷하게 사용
- 각 ROI r마다 사후 class 분포 값과 bounding box 예측값을 산출한다.
- 각 class k마다 r에 대한 Pr값인 detection confience를 부여한다.
- 각 class별로 non-maximum supression방법을 사용하여 산출
- SVD를 활용하여 detection을 더 빠르게 진행할 수도 있다.
- Faster R-CNN
- Fast R-CNN에서도 지역제한을 위한 클러스터링의 과정이 매우 느리다는 점이다.
- 지역과 영역들을 제한하는데 분할 알고리즘(selective search)이 아니라 신경망을 사용하는 방법입니다.
- use convolutional network to propose regions.
- Mask R-CNN
- YOLO
- YOLO v2
- YoLo v3
- Libaray code ref : https://machinelearningmastery.com/how-to-perform-object-detection-with-yolov3-in-keras/
5. Data _science_Bowl
key for the competition
- 생소한 game play 데이터를 사용하기 때문에 데이터에 대한 이해가 쉽지 않음.
- target값은 0.1,2,3으로 되어 있기 때문에 classification을 baseline으로 생각했으나, 많은 사람들이 regression도 사용함을 확인함
- feature selection은 top k best feature을 null importance를 통해 추출했다.
- SOTA 모델들을 ensembling한 model을 사용하는 것이 optimal approach 라고 생각함. 또한 boosting model을 사용하는 것이 tabular데이터를 다루는데 가장 선호되는 방법이며, neural network를 사용하는 것도 다른 관점으로 확인이 가능했다.
abount competition
- PBS KIDS app은 아이들이 학교생활과 라이프스타일에 대해 학습을 시킬 수 있는 신뢰도 있는 게임이다.
- 이 대회에서는 각 아이들의 데이터를 주고, 게임에서 평가의 score을 예측하도록 하는 것이다.
- 이 솔루션은 support discovering important relationships between different types of high-quality educational media and learning process.
approach
1. validation strategy
- K=5로 하여 KFold group을 installation_id를 기반으로 그룹지었다.
2. feature engineering8
- world를 numerical 형태로 바꿔줬다.
- add corresponing world of assesment
- accumulated number of different previous assessment
- add duration_std along with duration_mean
- add accumulated_assesment_attemps
- add combination of session_title_code of an assessment with corresponding accuracy_group assessment_accuracy_map
- add clip/activity/game duration mean and std
- no need to feature scaling as tree_based models are not affected by different scales of features.
3. feature selection
- eliminate high correlated features ( >0.99 correlated coeff)
4. modeling
- ensemble LightGBM, XGBoost, CatBoost, and Neural Network with 0.25 weighted each.
6. FUNDA_sales_prediction
- fin-tech 기업인 FUNDA는 상환기간의 매출을 예측하여 신용점수가 낮거나 담보를 가지지 못하는 우수 상점들에게 금융 기회를 제공하고자
- ~ 2019.02.28까지의 데이터를 활용하여 2019.03.01~2019.05.31까지의 3개월 매출을 예측해보고자 한다.
use model
- AR, MA, ARMA, ARIMA, Facebook proohet ..